L3 拐點將至,智能駕駛走向 VLA 分水嶺。
原本統一的「智駕第一陣營」分化出兩條道:
理想、小鵬、元戎是一隊,高舉 VLA 大旗,把 VLA 拼命推向前臺;
華為、Momenta、博世、卓馭等玩家卻站在對立面,給 VLA 毫不留情的潑冷水。
有人將 VLA 視為指路燈的同時,有人也在質疑 VLA 能否「發(fā)光」。
從以下三個問題,我們試圖把關于 VLA 的爭論點還原清晰:
VLA 能為智駕解決什么問題?
VLA 落地還面臨什么挑戰(zhàn)?
VLA 是否是智駕終局的最優(yōu)解?
智能駕駛早已過了「抄作業(yè)」的時代。沒有所謂的標準答案,大家都是在摸著石頭過河。
智駕當下比拼的,已經不是單純的技術路徑分野,而是技術路徑選擇背后,一場對于資源分配的策略和定力,比的是技術價值觀。
就像理想和元戎堅信,VLA 盡管進展慢,但上限一定會比端到端更高。
大家都在押注長期主義,但誰的長期主義會先顯驗,還要時間給出答案。
01、僅靠端到端,智駕進度條只能到 90%
端到端固然是條捷徑,它改寫了底層邏輯,從傳統規(guī)則驅動轉變?yōu)閿祿寗印?/p>
但當幾乎所有玩家都上了端到端這艘大船后,才發(fā)現,大船還不一定靠得了岸。
端到端兩大缺陷橫亙眼前:
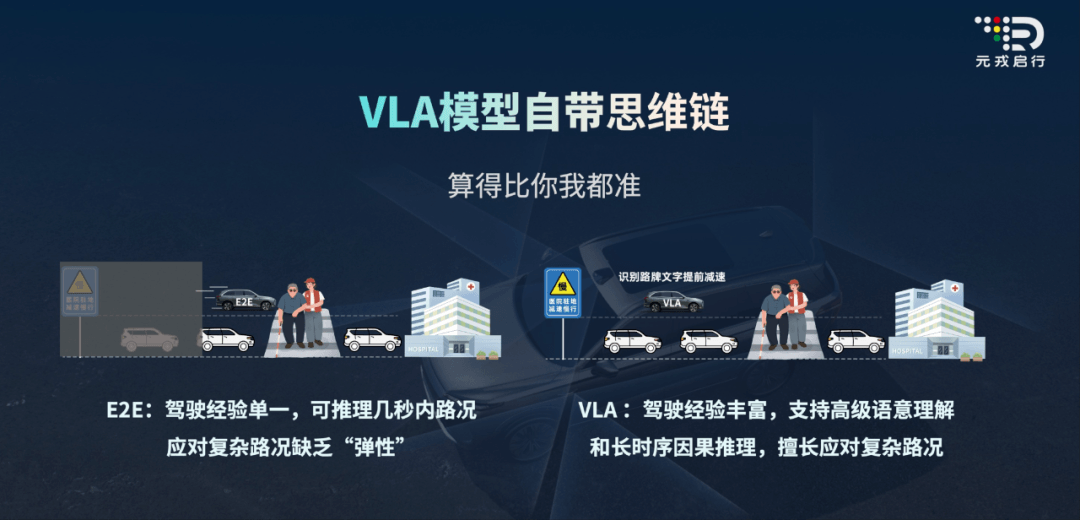
一是車為什么這樣動,說不清楚。
傳統端到端是一個黑箱,傳感器信號如何轉化為駕駛動作難以追溯,無法給出清晰的決策邏輯。例如車輛突然急剎,原因可能是探測到行人,也可能是把陰影誤判為障礙物,但系統并不會告訴你「為什么」。
二是沒見過的場景,就不會了。
端到端完全依賴數據驅動,沒見過的場景往往就不會處理。尤其在動態(tài)突發(fā)情況下,如行人突然橫穿馬路,系統只能依賴過往類似案例被動應對,反應滯后。此外,模型只能識別像素級特征(如紅燈形狀),卻無法理解語義級規(guī)則,比如紅燈等于禁止通行。
端到端可以解決智駕 90% 的難題,但剩下的 10%,卻怎么也跨不過去。
智駕安全顯然不能停留在 90% 的基準線,要向前推進,業(yè)內普遍的共識是用規(guī)則兜底,在端到端網絡之外寫入規(guī)則代碼,教會系統基本的交通法則,保證合理行駛。
但兜底更像是最后一道防線,面對錯綜復雜的極端情況,需要更加「治本」的方式。
于是,VLA(視覺-語言-動作大模型)躍入技術前臺。
這項技術最早由谷歌旗下的 DeepMind 提出,其標志性成果為機器人領域的 RT-2 模型,通過整合視覺感知、語言推理和動作控制,首次實現了從圖像觀察和文本指令到物理動作的端到端控制。
理想、元戎啟行將其引入智駕領域,目的也是借 VLA 能力突破端到端的瓶頸。
VLA 的關鍵點在于,在「VA(視覺-動作)模式」中間加入了「Language(語言)」這一關鍵橋梁。
理想智駕負責人郎咸朋強調,「L」指代語言學習能力,它并不是簡單的用語言做顯示的文字推理,而是用語言提供的數據學習做隱式的邏輯推理。
這就好比人與動物的區(qū)別,人的視覺能力、行動速度都不如動物,但憑借強大的認知和理解能力,能夠比動物更高一等。
相當于,VLA 的核心任務,就是讓系統具備長「思維鏈」,這落實到性能體驗上,會帶來三方面提升。
其一,更全維度的「路牌」理解。
這里的「路牌」不再局限于平面的交通標識,而是擴展到紅綠燈變化、交警手勢、施工錐桶等動態(tài)三維信息。比如,系統能夠識別潮汐車道標志,在擁堵路段也能順暢變道。
其二,更自然的語音交互。
用戶可以直接通過語音控制跟車距離、車速等,還能告知系統駕駛偏好。理想的「司機 Agent」甚至能記憶用戶習慣,用戶曾提示某路段應以特定車速行駛,系統在下次經過時會主動沿用,不用再重復指令,以此實現人車共駕。
其三,更前瞻的風險預判。
系統不再是遇到風險才被動響應,而是能通過視覺識別、語言推理提前感知潛在危險。比如看到前方路面有積水痕跡,會預判「可能存在涉水風險」并主動減速等。
VLA 玩家們都相信,VLA 是端到端的 2.0 形態(tài),一個形象比喻是:
端到端像猴子開車,會模仿人類動作,卻缺乏對物理世界的理解;
VLA 則像司機,甚至教練開車,既能理解規(guī)則,又能推理和靈活決策,從「學行為」進化為「懂意圖」。
只不過,現在的 VLA 優(yōu)勢還并不明顯。
郎咸朋強調,當前智駕任務還比較簡單,在 L3、L4 階段,智駕作為 Agent 要獨立完成復雜任務時,VLA 才會獲得碾壓性勝利。
但也正因如此,在「VLA 是否為行業(yè)終局答案」這一問題上,始終得打個問號。
02、VLA 可能還不在神壇上
當理想、元戎啟行高舉 VLA 大旗時,迎接它的并不是像「端到端」一般的技術光環(huán),而是多重質疑。
這場由 VLA 引發(fā)的輿論漩渦,一共有三層。
第一層是真假 VLA 之辯。關鍵角色是小鵬,有意思的是,小鵬早期并未高調舉起 VLA 大旗,它這張 VLA 玩家的身份牌還是元戎啟行翻開的,此前元戎啟行創(chuàng)始人周光表示,任何投入大算力、大參數模型研發(fā)的玩家,都大概率是 VLA 路線的潛在參與者。這就指向了小鵬。
直到小鵬 G7 Ultra 發(fā)布會上,小鵬才明確表態(tài),基于 3 顆圖靈芯片與雙激光雷達,小鵬 G7 Ultra 支持全場景 VLA,包括復雜路口決策、無車位泊車等功能,并在人機共駕模式下可以實現協同控制。
然而,盡管隸屬于 VLA 陣營,但小鵬把刀口對準的卻是「隊友」。
何小鵬聲稱,「只有我們做成了真正的 VLA,部分公司做成的是一個嫁接的 VLA。」
他對此解釋為,VLA 的落地需要數十億資金投入。相比端到端,VLA 要處理的是更高維度、非結構化的多模態(tài)信息,再將其轉化為駕駛動作決策,復雜度指數級提升。用幾個億只能堆出一個「微型 VLA」,本質上仍停留在端到端邏輯。
一句話,VLA 玩家都必須是資源稟賦型選手,需要技術先進,更需要大量資金。
某種程度上,小鵬用「純血 VLA」的角度,揭開了 VLA 水面之下的暗角。
這就來到第二層,VLA 的落地挑戰(zhàn)。博世智能駕控中國區(qū)總裁吳永橋解釋得很清楚,即 VLA 落地需面臨三大障礙:
多模態(tài)大模型的特征對齊存在挑戰(zhàn);
多模態(tài)的數據獲取和訓練十分困難;
當前所有的智駕芯片實際都不支持 VLA 模型。
尤其是第三點,吳永橋舉例,VLA 理想化部署需達到 7B-10B 參數規(guī)模,但現有智駕芯片帶寬有限。即便是一個 3B 模型,部署在英偉達 Thor 芯片上,頻率也難以穩(wěn)定維持在 10Hz。
10Hz 意味著系統每秒僅能完成 10 次感知與決策,放在駕駛場景中,就像一個「時常卡幀的機器人」。即使決策邏輯正確,但因為帶寬不足、反應滯后,行車過程中仍會頻繁出現延遲和卡頓,無法帶來流暢、可靠的駕駛體驗。
吳永橋并不否認 VLA 是個好方向,包括卓馭副總裁馬陸也認同 VLA 可以走通,但難度很大。
馬陸強調,VLA 中的「L」并不是簡單的語言大模型,不可能直接套用類似「通義千問」這樣餓現成模型,而是要從頭開始,練成一個理解智能駕駛的司機大模型,它需要完整理解物理世界的真實尺度,這需要資源,也需要時間。
種種論斷都構成一個基本事實:實現 VLA 并不容易。
而在此基礎上,Momenta 與華為對這一技術路徑的審視已經來到第三層,VLA 對于智駕的真?zhèn)涡浴?/p>
關于智駕是否有必要走 VLA 這條路,雙方都予以否定。
在 Momenta 創(chuàng)始人曹旭東眼里,VLA 只能算是錦上添花,還不足以扛起 L4、L5 的大任。最直接一點,VLA 對于安全性的提升或許能達到 5-10 倍,但 L4 規(guī)模化落地需要的是 100-1000 倍安全提升,顯然杯水車薪。
華為則堅定認為,VLA 這一從機器人領域引入的技術路徑,并不是為智駕而生。并且,由于 VLA 在空間感知與推理能力上存在天然短板,語言模型與動作決策本就難以對齊。
簡單而言,VLA 更像是一個偽命題。
相較之下,華為已經找到了新解法,在華為乾崑 ADS 4 上,打造出 WEWA 世界模型架構,通過端云結合的系統訓練,行為模型可以直接控制車輛,時延更低。
華為認為,世界模型才是通往智駕終局的正確路徑。
某種程度上,從小鵬、博世、卓馭再到 Momenta、華為,關于 VLA 的爭論,其實反應出各家差異化的技術邏輯,大多時候,技術路徑無關對錯,關乎選擇和資源博弈。
03、把雞蛋放進最近的籃子里
過去一年,端到端熱潮無疑讓智能駕駛的步子邁得更大,尤其是「車位到車位」的功能落地,不僅重新劃分了「第一梯隊」入場標準,也讓用戶清晰感知到智駕進步帶來的先進體驗。
然而,「車位到車位」之后,整個智駕行業(yè)進入了「功能停滯」的瓶頸期。
一方面,監(jiān)管給激進的智駕宣傳按下暫停鍵,四月份開始,工信部、市場監(jiān)管總局出臺《關于進一步加強智能網聯汽車產品準入、召回及軟件在線升級管理的通知》等系列新規(guī),對「自動駕駛」、「高階智駕」等用語予以禁止,把智駕安全提到絕對優(yōu)先層面,并規(guī)定車企每一次 OTA 更新,都需經過備案才能上線。
另一方面,L3 級智能駕駛政策還未放開,相當于,各車企、供應商還是停留在智駕體驗優(yōu)化層面,給 L2 后綴繼續(xù)添加「+」,用戶能感知到的「利己效益」并不明顯。
這也是 Momenta、卓馭等玩家目前并不看好 VLA 的主要原因,VLA 的確能在用戶體驗上「整花活」,比如語音控車、人機共駕,但大概率不能給智駕帶來成倍級的體驗革命。
站在 L2+的起點上,智駕行業(yè)每向前走一步,都會面臨更棘手的難題。越是到攻堅期,選擇哪條路就越發(fā)重要,畢竟,任何一條技術路線背后,都是對算力、數據的巨額消耗。
這也意味著,大家更愿意把雞蛋放進最近的籃子里。
一是押注確定性,幾乎所有玩家都堅定選擇了強化學習、世界模型的技術路徑,VLA 本質上與這兩者也并不沖突,在理想關于 VLA 的規(guī)劃版圖中,第四階段就是基于世界模型進行強化訓練,將系統打造成職業(yè)司機。
二是降低不確定性。智能駕駛的下半場,將是一場拼資金、拼技術、拼成本的拉鋸戰(zhàn)。因此,從有圖,到無圖,再到端到端路線,大家都是穩(wěn)扎穩(wěn)打走向下一階段,基于各自既定的技術價值觀,或者說,復用已有的數據和算法積累,確定下一步落子位置。
目前位列智駕第一梯隊的玩家們,可以看出打法各異:
理想、元戎啟行、小鵬選擇押注 VLA。強調高投入、算力密集型路線,追求 VLA 大模型的上限。
三家也的確通過資源配置為 VLA 鋪路,像小鵬通過自研圖靈芯片,算力超過 750TOPS,并打造出 72B 參數的基座大模型,為 VLA 大模型提供充裕算力支持;元戎啟行早期就研究 GPT 大語言模型,探索 VLA 方向,并聚焦英偉達 Thor 芯片的上車應用;而理想在端到端時期就乘上了「端到端+VLM」的列車,朝向 VLA 的方向。
另外,理想、小鵬都有自研人形機器人計劃,而 VLA 在具身智能與智能駕駛的通用性,也指向了二者對于 VLA 的長遠戰(zhàn)略布局。
而未選擇 VLA 路線的玩家們也是基于自身技術價值觀,錨定最優(yōu)解。
華為、地平線強調結構性解法,走體系化路線。華為憑借云端算力和 AI 大模型基礎,構建出 WEWA 世界模型,主打「無弱點」的原生架構;地平線基于自研高性能計算平臺征程 6P,強調軟硬一體優(yōu)勢,打造出「中國版 FSD」。
博世主打工程化落地能力,依托全產業(yè)鏈協同與車規(guī)級品控經驗,繼續(xù)強化一段式端到端,強調快速量產能力;
卓馭則是「性價比」標簽,聚焦主流車型需求,通過精簡傳感器配置與算法輕量化優(yōu)化,打造高適配性的入門級方案。
Momenta 繼續(xù)強調數據飛輪,強調商業(yè)可擴展性、成本可控。在「飛輪模式」驅動下,Momenta 將通過強化學習打造出新一代 R6 飛輪大模型。
在技術演進的道路上,每一項決策,都是取自于邊際成本與邊際效益的最優(yōu)計算結果。
話說回來,智駕行業(yè)上一次這么熱鬧,還是為「純視覺還是激光雷達路線」爭論不休,而爭論歸于平靜后,大家得到得共識是,純視覺也好,激光雷達也罷,只要能保證絲滑、可靠的智能駕駛,都是可行路線。
VLA 之爭同理,具體用哪種技術路徑,本就不是行業(yè)該糾結的落腳點。用戶在真實道路上能否感受到更平順的行駛質感、更可靠的安全保障,遠比選擇哪種大模型更重要。
今天,能把智駕體驗做到極致的玩家,才有機會在 L3 起跑時真正領先。
來源:第一電動網
作者:汽車之心
本文地址:http://www.155ck.com/kol/274646
文中圖片源自互聯網,如有侵權請聯系admin#d1ev.com(#替換成@)刪除。




先估價再買車,買的放心開的安心
您的詢價信息
已經成功提交我們稍后會聯系您進行報價!












 京公網安備
11010502033163號
京公網安備
11010502033163號