汽車產業已經“死氣沉沉”好久了,與“一年一小變,三年一大變”的互聯網產業相比,過去的幾十年來,它都沒有發生多少顛覆性的變化。然而,三十年河東,三十年河西,在即將到來的自動駕駛時代,汽車產業或將成為互聯網產業“羨慕嫉妒恨”的對象。
我們如此看好汽車產業在自動駕駛時代的前進速度,并不是因為汽車制造商掌握了什么絕技,而是自動駕駛系統所使用的核心芯片,正在以遠超”摩爾定律“的速度孜孜不倦地自我迭代著。

促使我們注意到自動駕駛芯片這種“進取心”的,是英偉達于10月11日發布的L5級無人駕駛計算平臺Drive PX Pegasus。對這款Drive PX Pegasus,如果用兩個字評價,那就是“牛逼”;用四個字評價,就是“相當牛逼”。要想知道它究竟有多牛逼,還得先跟英偉達的現有產品做個比較——目前,特斯拉的Autopilot 2.0上使用的Drive PX 2每秒鐘可完成24萬億次深度學習計算操作,而Drive PX Pegasus每秒鐘可完成的深度計算操作是320萬億次!也就是說,在深度學習計算這個最重要的能力上,Drive PX Pegasus比Drive PX 2強出12倍還多!
從發布時間上看,Drive PX Pegasus比在2016年1月份的CES展上亮相的Drive PX 2晚了21個月。21個月計算能力增強12倍,這算是徹底震撼了“摩爾定律”——根據摩爾定律,21個月以內計算性能翻一倍才是“正常”的。
再回過頭去看從Drive PX 到Drive PX 2的進步,時間跨度是從2015年1月份到2016年1月份,剛剛12個月;而在這12個月里,英偉達無人駕駛計算平臺的計算能力也是進步了10倍(深度學習計算性能從2.3萬億次/秒增長到24萬億次/秒)! 這個進步速度,仍然是超出了摩爾定律的“解釋能力”。
也難怪,英偉達創始人黃仁勛曾多次在公開場合說“摩爾定律已死”。不過,與此前很多IT界人士質疑“摩爾定律是否已經過時”是暗指芯片性能的進步速度正在放緩不同的是,黃仁勛所說的”摩爾定律已死“,意思是,在AI時代,GPU的進步速度要超過在摩爾定律下CPU的進步速度。
GPU換代周期縮短,增長倍率變大
從24萬億次/秒到320萬億次/秒,Drive PX Pegasus的深度學習能力已經是誕生于21個月之前的“上一代”的13.3倍;與更早的Drive PX的相比,在不到3年的時間里,它的性能已經增長了將近140倍!
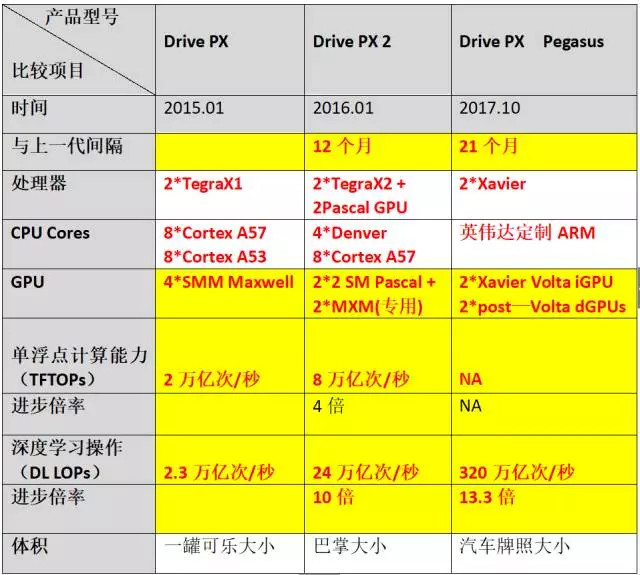
或許,有細心的人要質疑了:摩爾定律說的是芯片的計算能力,可你這里提到的Drive PX系列無人駕駛計算平臺,都是集成產品,而非“原始芯片”,因此不能拿它的“進步曲線”來跟摩爾定律做比較。 這個質疑是有道理的,不過,我正想補充的是,Drive PX系列的計算性能“每一代比上一代進步10倍”,除去CPU的配置顯著提升外,更關鍵的原因正是它們所用的GPU的性能也提升了大約10倍!
GPU的計算性能與其在設計時采用的架構模式高度相關。Drive PX采用的GPU是基于Maxwell的TeslaM40;Drive PX 2采用的GPU是基于Pascal的TeslaP100;Drive PX Pegasus采用的GPU有兩顆是基于Volta的TeslaV100(上表中提到的Xavier,是在TeslaV100的基礎上集成而來的Soc),還有兩顆是尚未發布的繼Volta之后的“下一代”。
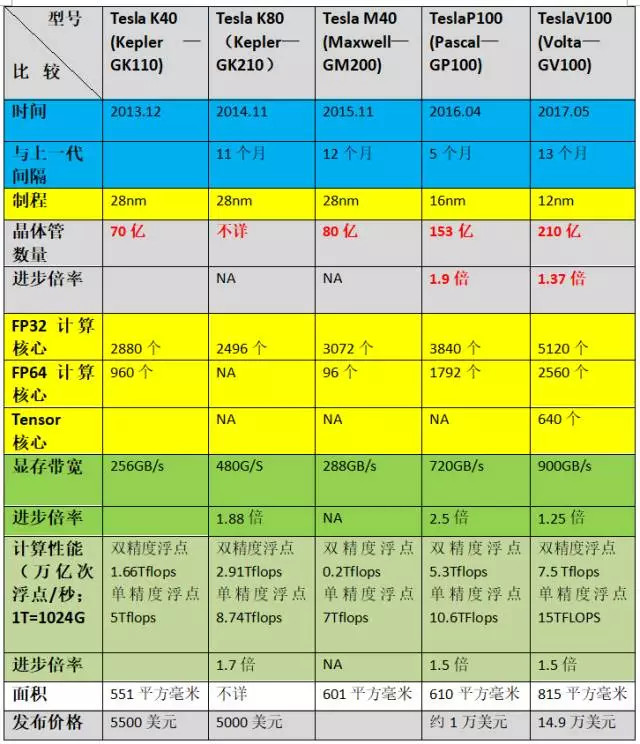
從上表可見,從2013年12月至2015年12月這兩年,GPU的提升速度很慢,甚至,與前代相比,TeslaM40在某些單項指標上還出現了嚴重倒退。但在TeslaM40之后,GPU的更新明顯加快——代際更新周期通常為6-12個月,計算性能的進步倍率通常在1.5倍左右。如果把周期延長到18個月,TeslaV100相比于TeslaM40,晶體管數增長至后者的2.6倍,顯存帶寬增長至后者的3.1倍,單精度浮點計算性能超過后者的2倍。
各單項指標的進步組合在一起后,在“乘數效應”的作用下,據英偉達方面曾在2016年的發布會上宣稱,從TeslaM40到TeslaP100,GPU的整體性能提升了大約10倍;此外,據專注于人工智能的科技媒體雷鋒網早先的報道,相比于基于Pascal架構的TelsaP100,基于Volta的TelsaV100將深度學習訓練速度提升了12倍、深度學習推理速度也提升了6倍,綜合性能提升也在10倍以上。
6-12個月,芯片(GPU)的新能就曾提升10倍,實在可怕!由于GPU基本上是英偉達的天下,在這里,恐怕已經有一個“黃仁勛定律”了吧?IT界的其他人困惑“如果摩爾定律消失,我們該何去何從”的時候,大多充滿了憂慮,而黃仁勛在說“摩爾定律太老了,太慢了,GPU才是全新的‘超級摩爾定律’”的時候,應該是志得意滿的吧?——言外之意是,屬于英特爾的時代已成為過去,屬于我黃仁勛的時代正在到來。
作為佐證的是,9月27日上午,在NVIDIA全球GTC北京站上,黃仁宇特別強調:“我們不會做那些每一次好一點點的通用性的處理器(CPU),而是要做在一些專門的領域,性能極好的處理器(GPU)。” 在黃仁勛眼里,摩爾定律下CPU性能的“每18-24個月翻倍”居然只是“每次只好一點點”,這是在公然羞辱英特爾嗎?
宿敵的芯片也遵循“黃仁勛定律”
對黃仁勛反復“鄙視”摩爾定律并“詛咒”它“已死”,作為摩爾定律的“既得利益者”的英特爾,肯定會回復一個大大的“不服”,然后,再連加三個“感嘆號”。
9月19日,在北京舉行的“英特爾精尖制造日“活動上,英特爾向公眾展示了10nm晶圓,并透露他們已經前瞻到了5nm制程。通過展示這些看家本領,英特爾旨在強調“摩爾定律不僅沒有過時,而是一直在向前發展’。
不過,嘴硬歸嘴硬,眼睜睜地看著昔日的“小屁孩”英偉達的股票一年漲了2倍、兩年漲了8倍,曾經“一統江湖”的英特爾一定是很焦慮的。它已經錯過了移動互聯網時代,不能再錯過AI時代了。英特爾在2016年以167億美元收購世界第二大FPGA公司Altera、在2017年以153億美元收購全球第一大ADAS供應商Mobileye,正是為了應對這種焦慮。
在AI領域,FPGA因具有“可編程”、靈活性強及功耗低的特性,在某些方面具備跟GPU一爭高下的能力。然而,從“代際更新“的角度看,FPGA仍然跳不出摩爾定律的”局限性“。
下圖為英特爾旗下Soc FPGA產品的Arria 系列
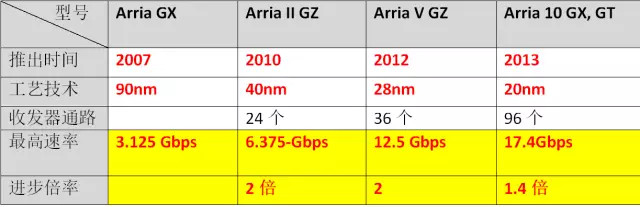
Arria 系列Soc FPGA芯片在更新換代時,仍然遵循了“每18-24個月計算性能翻一倍”的老規律。
不過,英特爾的另一個孩子Mobileye所造的芯片,在進步速度上卻“很爭氣”。
Mobileye生產的EyeQ系列芯片,是為自動駕駛汽車的ADAS系統專用的,其中,EyeQ3曾經用在特斯拉的Autopilot 1.0上。Mobileye很能沉得住氣,在這個熱錢與泡沫齊飛的浮躁年代里,它卻堅持“八年磨一劍”,自1999年成立后就一直踏踏實實做研究,直到2007年才發布了第一款擁有ADAS的芯片EyeQ1。但他的芯片一經發布,就開始了“指數級成長”。
下圖為Mobileye EyeQ系列芯片的“迭代”路徑:
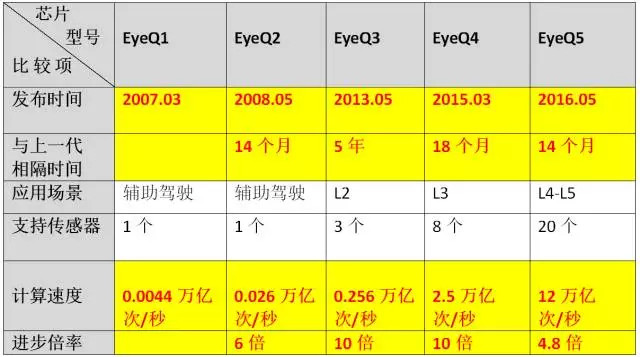
從EyeQ1到EyeQ2,芯片的計算新能在14個月內增長至原先的6倍,遠遠超出摩爾定律;
從EyeQ2到EyeQ3,計算能力在5年里增長至原先的10倍,雖然速度變慢,但跟摩爾定律相比并不算太遜色(按摩爾定律,24個月翻一倍的話,應該是48個月翻兩番,計算能力增長至原來的4倍,或者,18個月翻一番,應該是54個月翻三番,增長至原來的8倍);
從EyeQ3到EyeQ4,計算能力在兩年內增長至原先的10倍;
從EyeQ4到EyeQ5,計算能力再在1年內增長至原先的將近5倍......
這些都說明,雖然英特爾和Mobileye長期以來都視英偉達為勁敵,但它自家產品的進化,卻依然得遵守了“黃仁勛定律”。
在收購Mobileye之前(2016年8月),英特爾曾以4.08億美元收購了AI芯片創業公司Nervana Systems,并聲稱將在2020年之前將深度學習訓練速度提升100倍。在摩爾定律主宰的“舊時代”里待久了的人,可能會覺得“提升100倍”是吹牛逼,但在AI時代的“黃仁勛定律”下,三年提升100倍,其實不是多困難的事情——
因為,6*6*6=216,再不濟,也可以通過5*5*5=125來提前實現目標。
TPU:速度已經很牛逼,但加速度還需努力
很早之前,谷歌就意識到GPU更適合訓練,卻不善于做訓練后的分析決策,因此,它得自己開發一款專門用于做分析決策的AI芯片。在低調使用了一兩年后,在2016年5月份召開的Google I/O大會上,這款專用芯片TUP終于閃亮登場了。
谷歌聲稱TPU(以下簡稱TPU 1)的運算速度“比當前CPU和GPU快15-30倍”,但很快遭到黃仁勛及其擁護者的“打臉”,他們紛紛表示,谷歌是拿自己新出的產品跟英偉達兩年前的舊產品TeslaK80做比較,不太厚道。甚至,直到谷歌在2017年推出新一代TPU即TPU2時,英偉達方面也稱,他家的最新款GPU Tesla2V100在計算性能可以秒殺TPU2。
尺有所長,寸有所短,TPU是滿足特殊功能的專用芯片,那它去跟GPU做PK,似乎也不太妥當。現在,我們放下這種不同產品之間的橫向比較,只在同種產品的代際間做縱向比較。
別的不說,就看最重要的計算能力:TPU 1每秒可提做23萬億次16位整數的運算提,TPU 2可以達到每秒45萬億次的浮點運算。計算能力只增長了一倍。
TPU 1的開發時間為2013年前后,TUP 2的開發時間暫無可查詢。如果TPU 2的開發時間在2015年之前,TPU 1到 TPU 2,芯片計算能力的提升幅度,剛好在摩爾定律的范圍內,或者,比摩爾定律稍微快一點,但也沒有明顯優勢;但如果TPU 2的開發時間在2015年之后,那么,從TPU 1到 TPU 2,芯片計算能力的進步速度是落后于摩爾定律中的速度的。
盡管谷歌口口聲聲稱自己的TPU比GPU“快得多”,但在加速度方面,它充其量只能跟摩爾定律下的CUP相比,跟GPU和EyeQ的計算能力“每12-24個月翻10倍”的加速度相比,它還是慢了很多。
在“黃仁勛定律“下,芯片的架構研究很重要
最近,無人駕駛初創公司地平線創始人余凱在新智元舉辦的一次論壇演講中談到“新摩爾定律”。“最近大家也發現在物理上面,可能摩爾定律已經在逼近它的物理極限,英特爾本身自己也在減少自己往前遞進的速度。這里打一個問號,我們怎么樣保持摩爾定律?”
余凱自己給出的答案是:實際上還是可以做到的,手段不是通過物理上的工藝提升,而是通過軟件算法的變革帶來研發一些新的架構。隨著摩爾定律越來越接近工藝極限,芯片的架構設計變得越來越重要。
“如果能研發出新的架構,在特定的目標應用場景上面,我們還能不斷地往前發展。打個比方,我們人類的大腦實際上是有通用處理器的部分。有很多專用的硬件,比如聽覺的、視覺的神經網絡結構,包括有研究在三年前發現了在人腦里面有一個地方是專門用來做定位的。就是說,因為特殊目的去定義的這個硬件,使得你對特定的問題效率可以更高,新的摩爾定律可以繼續往前奔跑,這個是新的摩爾定律。”
余凱這里所說的”新摩爾定律“,實際上就是本文在前面提到的”黃仁勛定律“。而他所說的通過”研發新架構“來改變進步速度,恰恰可以從英偉達的GPU隨著架構從Kepler—Maxwell—Pascal—Volta改變,GPU的整體性能也飛速進步中得到印證。
一點疑問
前文討論“摩爾定律”和“黃仁勛定律”,都是單從產品性能、技術進步的角度談,卻回避了價格的問題。摩爾定律的一個前提是“價格不變”,但AI芯片在更新換代時,價格往往會有很大的提升,比如,GUP TeslaP100發布時的價格是1萬美元,而 TeslaV100的價格則是14.9萬美元,完全不在一個量級。
從以往的規律看,新開發芯片的可以通過出貨量的增長降下了,只是,不太確定,TeslaV100從天價降到“平民價”,需要達到怎樣的出貨規模才可以實現?需要等待的周期是多長?
來源:第一電動網
作者:建約車評
本文地址:http://www.155ck.com/kol/57709
本文由第一電動網大牛說作者撰寫,他們為本文的真實性和中立性負責,觀點僅代表個人,不代表第一電動網。本文版權歸原創作者和第一電動網(www.155ck.com)所有,如需轉載需得到雙方授權,同時務必注明來源和作者。
歡迎加入第一電動網大牛說作者,注冊會員登錄后即可在線投稿,請在會員資料留下QQ、手機、郵箱等聯系方式,便于我們在第一時間與您溝通稿件,如有問題請發送郵件至 content@d1ev.com。
文中圖片源自互聯網,如有侵權請聯系admin#d1ev.com(#替換成@)刪除。




先估價再買車,買的放心開的安心
您的詢價信息
已經成功提交我們稍后會聯系您進行報價!








 京公網安備
11010502033163號
京公網安備
11010502033163號