在輔助駕駛的黃金三角——數據、算法、算力中,數據被普遍視為驅動大模型進化的「燃料」。
然而,在數據驅動的這條主軸上,車企與供應商似乎面臨著不同命運。
車企憑借終端用戶的天然觸角,構建起數據護城河:理想、奇瑞、吉利等車企近期都宣稱數據量達到了 1000 萬 Clips;小鵬更是把這一數字拉到了兩倍:2000 萬 Clips。
馬斯克認為,對于端到端輔助駕駛,用 1000 萬個 Clips 進行訓練,系統會有驚人表現。
這似乎意味著,車企憑借數據積累將更容易抵達大模型的升維奇點。而供應商除非獲得車企信任,否則在 1000 萬 Clips 的數據積累上勢必要下更多功夫。
但數據驅動的競爭邏輯,從來不是單純的「以量取勝」。
地平線創始人兼 CEO 余凱一針見血指出,「AI 時代,99% 的用戶數據其實不值得學習」。
這條「反共識」觀點背后,是數據價值的深度重構。
由此,在端到端架構與生成式 AI 的沖擊下,數據戰爭的勝負手不再是「誰擁有更多燃料」,而是「誰能用 1% 的數據實現 100% 的效能躍遷」。
后端到端時代,有必要對數據課題重新審視了。
01、1000 萬 Clips 等于「職業老司機」
在明確 1000 萬 Clips 的意義之前,需要先明晰「Clip」的含義。
「Clip」通常指向一個特定時間段內的多模態數據片段,這些數據由激光雷達、攝像頭、毫米波雷達等傳感器同時捕獲。
而這一概念通常與 4D 標注技術密切相關。
所謂 4D 標注,是在傳統三維空間坐標之外,還加入了時間維度。對比以往的單幀 2D 框、3D 框標注,4D 標注除了要記錄當前幀的車輛坐標,還要追溯前幾幀的運動軌跡,因而能夠更加全面與準確地描述物體在空間中的運動情況。
一位業內人士指出,Clip 指一段時間的視頻切片,時間取決于模型設計,一般在 30 秒左右。
毫末智行認為,4D Clips 的數據規模對比此前 2D、3D 數據標記方式,達到了百倍級的驚人增長,是當前價值最高的感知數據形態。
由此,1000 萬 Clips 模型,意味著其擁有 1000 萬個信息高密度的視頻切片,具備兩個維度的特點。
一是極端場景覆蓋率高。
數據包含難以處理的極限場景,例如高難度、連續 S 彎的山路;180°發卡彎等大曲率彎道;通過岔路口并連續變道進入轉彎車道場景等。
二是數據場景分布合理。
理想汽車將道路行駛中的場景,分為靜態場景和動態場景,靜態場景包含城市主干道、國省道、輔路等,動態場景包含繞行、變道等。在系統訓練過程中,按照靜態和動態兩類場景進行篩選,將不同復雜程度的場景均涵蓋其中,使得輔助駕駛的場景處理能力更加擬人和高效。
這是一個給系統投喂經驗的必要過程。
數量級大小相當于一個人駕駛經驗的多少,如果從體驗程度出發,可以將司機能力劃分為普通司機、熟練司機、職業老司機三個級別。
理想認為,1000 萬 Clips 模型意味著系統具備了一名職業老司機的能力,能夠臨危不懼,以高超的駕駛技術安全、舒適、高效地開車。
由此,這是大模型進階的關鍵節點。
實際上,除了理想,小米、吉利、奇瑞在展示數據儲備時也將 1000 萬 Clips 數據作為重要論據。
這一論據主要傳遞了兩點關鍵信息:
一是用數據規模傳遞系統可靠性及未來潛力,增強用戶信任。
在 AI 時代,輔助駕駛依靠大量數據驅動。1000 萬 Clips 代表著豐富的駕駛場景和數據量,能讓輔助駕駛系統學習到各種復雜路況和駕駛情況。
以理想 AD Max V13 為例,用戶可以明確感受到 1000 萬 Clips 訓練下,系統不再是基于規則呆板得執行程序,而是有了一種「活人感」。
比如系統變道控車時會遵循更合理的策略,避免變道博弈失敗,在提升變道效率同時提升用戶乘坐的舒適感,并減少對旁車的影響。以及在繞行二輪車場景下,系統會更早對二輪車行駛意圖做出判斷并完成繞行,速度控制更加精細、平順。
二是用大模型的體驗提升印證數據驅動方式的高效與先進性。
在數據驅動下,理想輔助駕駛水平提升有目共睹,成為首批率先達成「車位到車位」成就的車企之一。
這背后,是訓練數據量的線性增長曲線。
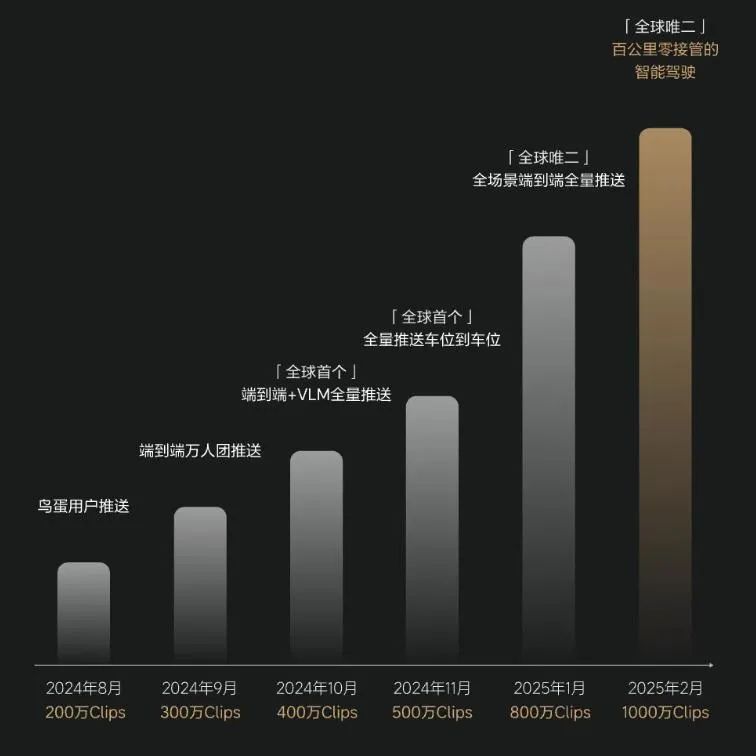
自 2024 年 7 月底開啟千人團內測以來,理想僅用 7 個月時間,完成了 100 萬 Clips 初版模型向 1000 萬 Clips 模型的優化迭代。
端到端技術路徑的持續演進下,數據模型將在不斷膨脹下,反哺輔助駕駛性能躍入 L3 時代。
而 1000 萬 Clips,也會成為輔助駕駛第一梯隊的核心量化條件。
02、數據「提純」技術是關鍵
1000 萬 Clips 有個核心限定詞:高質量。
輕舟智航 CEO 于騫曾在 2025 電動車百人會上公開表示,數據訓練的關鍵在于覆蓋維度與數據質量。
前者指「泛」,后者指「精」。即在數據清洗過程中,要剔除掉重復場景與不合理駕駛行為數據。
這點與余凱的反共識觀點異曲同工,「99% 的人類司機數據不值得學習」的金句背后,是指大部分人類司機的駕駛技術與習慣并不合理,存在闖紅燈、隨意變道等不良行為。
建立嚴格的數據篩選和評估標準成為必要舉措。
于騫就強調,需要通過專業評分系統從 100 名司機中篩選出 1 名最優駕駛者(如禮賓車司機級)進行數據對齊。
理想汽車的做法亦是如此。
從 116 萬用戶的真實駕駛數據中,理想依據駕駛順暢度、操作規范性等維度建立篩選標準,最終僅將 5% 的高質量數據納入「五星老司機」的訓練集。
這一「極致提純」的過程,折射出輔助駕駛領域的核心矛盾:數據價值不在于量的堆砌,而在于質的穿透。
倒推來看,數據難題的本質并非「缺水」,而是「水質凈化」。這就好比淘金者必須先囤積大量礦砂,才能通過篩洗提煉出黃金。
數據提純的前提,是擁有足夠龐大的「原始水源」。
當前車企與供應商獲取「水源」的方式主要有三種:
第一種是對車企更友好的眾包模式。
正如理想一般,讓用戶授權后,匿名采集用戶的真實駕駛數據。
特斯拉的影子模式已經打好了樣。用戶在駕駛車輛時,系統在后臺模擬駕駛決策,將其與駕駛員實際操作進行對比,若兩者不同則上傳相關數據,用于優化算法。
某種程度上,車賣得越多,用戶開得越多,數據資源就積累得越多。
關鍵一點,在眾包模式下,車企還能把用戶接管數據的驅動閉環(回傳-存儲-分析-訓練)也全部打通。
但上游的智駕供應商注定與大批量數據資源之間隔著一道坎,這道坎關乎車企信任。
Momenta 創始人兼 CEO 曹旭東說過一句很體面的話:供應商與車企之間信任關系的建立,關鍵在于供應商能否為用戶和客戶創造價值。
說白了,數據主動權不在自己手里,想要獲得數據資產,得看表現。
既然不能輕易調動水源,就只能自己建水庫——也就是第二種方式:組建專業的路測團隊自采數據。
這已經是輔助駕駛供應商的必有任務。即將傳感器安裝在測試車上,在行駛過程中感應周圍環境,進行物體辨識、偵測與追蹤,并結合高精度地圖數據采集數據。據悉,一輛測試車每天路面測試產生的數據可達 TB 級。
除了采集,路測車隊的另一核心任務在于測試。因此,自采數據的優勢一方面在于精準控制采集場景,比如根據研發需求定向采集特定場景數據(如暴雨、隧道、復雜路口等),另一方面在于提升訓練效率,針對長尾場景的數據被訓練后,系統可以在實地測試中反哺算法迭代。
當然,自建車隊采集數據的成本注定會隨著數據累積水漲船高。
看得見的是車隊數量、設備配置、人員薪酬等硬性成本,看不見的則是數據存儲與傳輸的隱形成本。
有媒體報道過,一家頭部智駕供應商企業每年回傳數據的流量費以億元為單位,云端數據存儲成本每月可能數百萬到上千萬元。
可以說,自采數據就像在走獨木橋,在人力、財力耗費大量成本的同時,還伴隨著采集極端場景的高安全風險。
因為在真實道路上,暴雨、暴雪、夜間強光等極端天氣場景出現概率極低,需要耗費大量精力才能采集到。Waymo 就曾披露過,其路測車隊需累計行駛超 10 億英里才能覆蓋約 2.5 萬種長尾場景。
由此,第三種數據采集方式——數據仿真,走進輔助駕駛玩家們的視野。
即在仿真平臺中通過生成式 AI 技術,批量生成數百萬種虛擬場景,來覆蓋真實路測中難以遇到的極端情況。
AI 企業在這點上掌握先發優勢,比如商湯絕影打造的「開悟」世界模型,基于一個 BEV 視角下的初始主車和他車位置,就可以生成主車視角下 11V(11 個攝像頭)的傳感器仿真數據,并且 1 個 GPU 產生的仿真數據相當于 500 臺量產車的數據采集效果。
可見,仿真數據通過低成本、高安全、廣覆蓋的特性,能夠解決真實世界「測不全、測不起、測不快」的難題。
但這僅局限于未來的理想狀態,目前數據仿真技術仍主要扮演數據采集過程中的輔助角色。
不過,可以確定的是,隨著輔助駕駛向 L3、L4 級持續進階,優質的數據資源將越來越稀缺,這也意味著三種「找水源」方式的權重也將發生動態變化。
就像馬斯克篤定認為,現實世界中能夠用于 AI 訓練的數據幾乎已經被消耗殆盡,而數據仿真才是未來數據驅動的有效解法。
03、后端到端時代,打的還是數據資源戰
在輔助駕駛的當下語境內,行業討論的技術焦點不再是「你端沒端」,而是「端到端之后,下一步該研究什么?」
后端到端時代,行業正呈現出全新生態。
最直觀一點,在量產落地場景上,城區智能輔助駕駛的擂臺已經被選手擠滿了,主要區別在于搭載哪種芯片,基于多大算力,滲透到多少萬車型。
而在更高一層的「車位到車位」競技場,華為、理想、小鵬、Momenta、極氪等多名玩家也已經沖線。
L3 成為了新的挑戰門檻。
投射到技術層面上,一些技術趨勢浮出水面,逐漸成為共識。
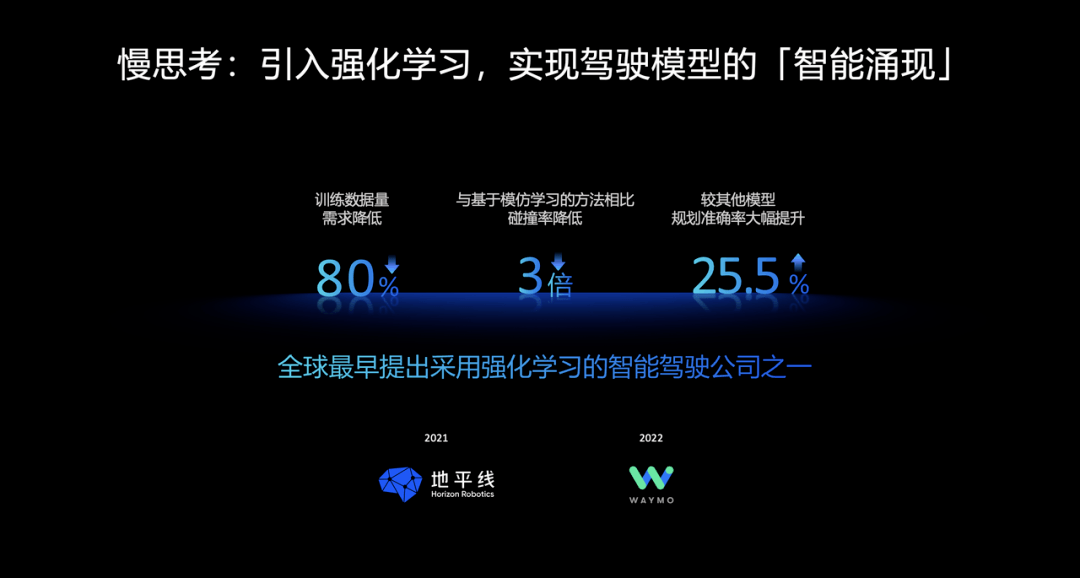
一是從模仿學習到強化學習。
簡單而言,模仿學習是依賴人類駕駛數據的「標準答案」,被動模仿人類司機,而強化學習是通過虛擬環境的「獎懲反饋」,主動地試錯探索。
強化學習的最直觀優點,在于系統可以自主探索人類沒有教過的復雜場景,讓駕駛決策更加靈活智能。
在地平線提出的輔助駕駛算法「快思考、慢思考」路徑中,就是引入強化學習來實現駕駛模型的智能涌現。
Momenta 也計劃在今年下半年,推出基于強化學習框架的 Momenta R6 飛輪大模型。
二是從 VLM(視覺語言模型)到 VLA(視覺-語言-動作模型)。
理想是 VLA 的代表選手。李想曾將從規則算法到「端到端+VLM」,再到 VLA 的技術路線進化類比為昆蟲動物智能、哺乳動物智能、人類智能三個階段。
相當于,基于 VLA 路徑,系統表現得像專職司機,可以隨時聽懂并執行「開快點、左拐」等指令,也能在陌生地庫漫游尋找車位。
相比 VLM,VLA 在可解釋性、泛化性及復雜場景適應性上都有顯著提升。
由此,在算法、算力、數據三者的命運共同體之下,算法的演進同樣倒逼數據產生新的化學反應。
但主軸依然還是:數據閉環。
可以說,現在沒有一家車企或供應商能繞開數據閉環。
曹旭東做過一個簡單總結,在輔助駕駛這條路上,百萬數據大概能做個演示樣品,千萬數據大概能做一個及格產品,上億數據大概能做到接近比較好的一個產品,十億級別能做到超越人類水平的產品。
小鵬做好了準備,在達到 2000 萬 Clips 數據節點后,年底預計數據存儲量會飆升至 2 億 Clips。
毫無疑問,海量且高質量的數據是推動智能駕駛前進的核動力。
所以無論是強化學習還是 VLA,兩條技術趨勢對于高質量數據的渴求是不變的。
只不過,如今關于數據探討的分歧,已演變為在「從真實數據中提取有效數據」與「從仿真數據中生成有效數據」之間,二者權重該如何權衡的博弈。
目前來看,兩者并重是最優解。
一方面,強化學習生長的虛擬環境同樣需要高質量數據充當數據采集源頭。
另一方面,仿真模擬和 AI 生成數據的質量目前還不如實車行駛收集的數據。
余凱就指出,數據差別的關鍵在于,人類還無法教機器充分認識世界,也無法在虛擬世界中完整復刻現實。
在小馬智行創始人樓天城看來,真實駕駛數據對建立世界模型的作用存在局限性。世界模型若想真正理解真實世界,不僅需要駕駛數據,還需大量涵蓋環境、生活等多維度的真實數據。這就如同 DeepSeek 能夠解決物理問題,并非僅靠學習物理知識,而是融合了物理、化學、生物等多學科內容。
可以確定的是,輔助駕駛的未來發展離不開世界模型,且世界模型的精度直接決定了車載模型的上限。
不過,在數據應用過程中,如何規避幻覺數據干擾、構建科學的評價體系,仍是一個持續性探索過程。
而如果跳出技術細節用更宏觀的視角看待這個過程,各玩家對于高質量數據的追求背后,其實是對龐大資源的不斷消耗,關乎人力、物力、財力。
曹旭東在采 訪中直言,現在一年投入小幾十個億,就能做到第二梯隊或準第一梯隊水平,但再往后,要幾百億才能做到同樣水平。如果要做到量產 L4 自動駕駛,每年的研發投入至少是百億甚至幾百億。
輔助駕駛賽道越向深水區延伸,越需要具備「高舉高打」的戰略視野。
特斯拉已經做了示范,但極高的競爭壁壘下,還沒有玩家能抄到特斯拉的作業。
因此輔助駕駛開啟淘汰賽后,規則很清晰,競爭格局也很清晰。
由技術投入強度、數據積累速度、場景覆蓋廣度構成的核心篩網,讓頭部玩家與追趕者的分化不斷加速。
在當前這個關鍵賽點上,一個最直觀的實力刻度已經出現,即誰先邁過 1000 萬 Clips 的數據門檻,誰就能拿到輔助駕駛第一梯隊的入場券。
來源:第一電動網
作者:汽車之心
本文地址:http://www.155ck.com/kol/269315
文中圖片源自互聯網,如有侵權請聯系admin#d1ev.com(#替換成@)刪除。




先估價再買車,買的放心開的安心
您的詢價信息
已經成功提交我們稍后會聯系您進行報價!









 京公網安備
11010502033163號
京公網安備
11010502033163號